A version of this translated article has been published on sspai.com.
這篇文章關於一個大語言模型(LLM)的前端:SillyTavern。
LLM 流行以來,有人視之救世主,有人視之天啟騎士,有人視之資本騙局,但無論如何,所有人都在談論它。我通常對新事物都相當遲鈍,對 LLM 的態度也大致在「居然這也能幹」和「居然連這都幹不好」之間搖擺。我不像我的朋友 Losses 一樣,對 LLM 從本體論到方法論都有相當深刻的研究。要說至今有什麼心得,我覺得對非 AI 專家的人來說,倘若真想讓 AI 幫到自己什麼,嘗試更好地理解 LLM 適合做什麼,可能是最能節省自己時間和金錢的途徑。而就是在這件事上,SillyTavern(ST)給了我很多啟發。ST 本質上是一個用於 AI roleplay(角色扮演)遊戲的 LLM 前端程序,但我意外發現它其實可以用來做幾乎任何工作,而我之所以感到它對許多工作來說,其實是最好的模式,那些長處恰恰來自於它針對角色扮演的設計。回頭想來,這這件事情本身是一個多麼巧奪天工的隱喻:我們作為人類所行的種種工作,難道不也只是扮演了一些角色而已?我們無法隨時切換自身的角色,那是受技能和知識所限,而人類的多數知識和技能,說到底也要靠語言來傳達。大語言模型恰恰是提純的語言,非技能的語言,非知識的語言,這些限制對它們來說不外乎懸崖之於飛鳥。
起初這只是一個無心的收穫,本文描述的用法大部分也並非 ST 的主流使用場景。只是似乎沒在網上見到多少相關的討論,實在可惜,故有此文。
SillyTavern 是什麼
雖然前面說了要講非主流的使用方式,但首先還是需要先講清楚 ST 和它的「主流」使用場景是什麼。首先,它本質上是一個 LLM 的前端,不提供模型,只提供交互的框架和介面。你需要提供自己的 LLM API 並在前端的介面中與 AI 進行交互。類似的產品還有 LibreChat,只不過後者提供的是類似原版 ChatGPT 的單純對話式交互介面,而 ST 的設計目標則是 AI 角色扮演。
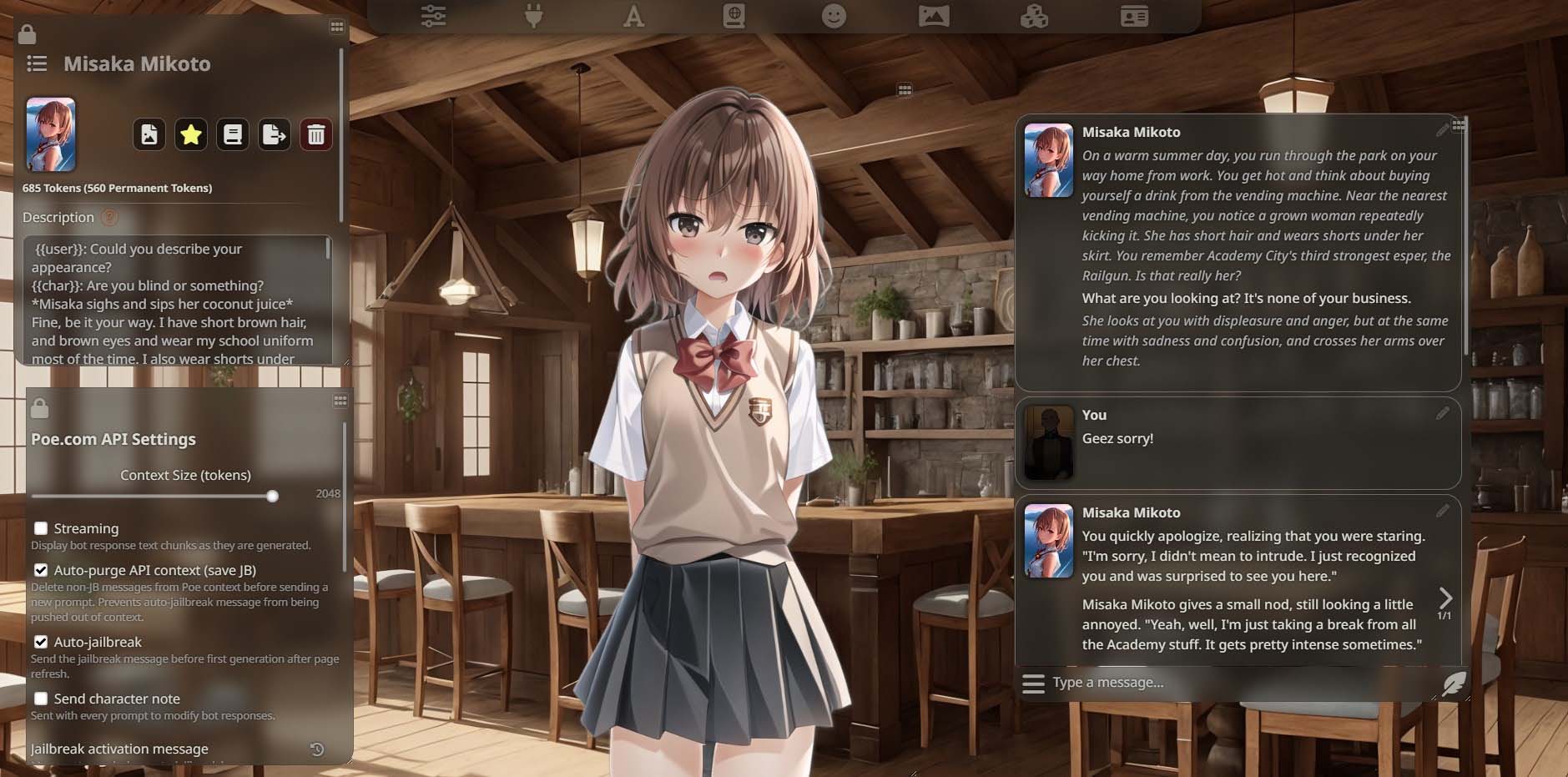
SillyTavern 的典型介面
ST 的前身是 TavernAI,是一個用 AI 來玩 RPG 冒險遊戲的程序,你可以設計好角色、環境、世界觀,讓 AI 扮演角色和旁白推進故事。ST 也繼承了這個框架,但在這基礎上添加了更複雜的功能和插件系統,也因此使得一些非主流的用法得益。
角色扮演聽起來不難,但要保證輸出的穩定和合理,背後其實有相當多要考慮的事情。ST 也因此圍繞這個使用場景提供了大量的設定選項,如果是剛上手,很容易被五花八門的按鈕和選項搞得一頭霧水。不過,儘管複雜,我認為 ST 背後的設計邏輯還是相當清晰的。本文的下一節將逐一介紹 ST 設定的框架中一些關鍵的元素,因為這會是理解 ST 工作方式的必要語境。
SillyTavern 的設定框架
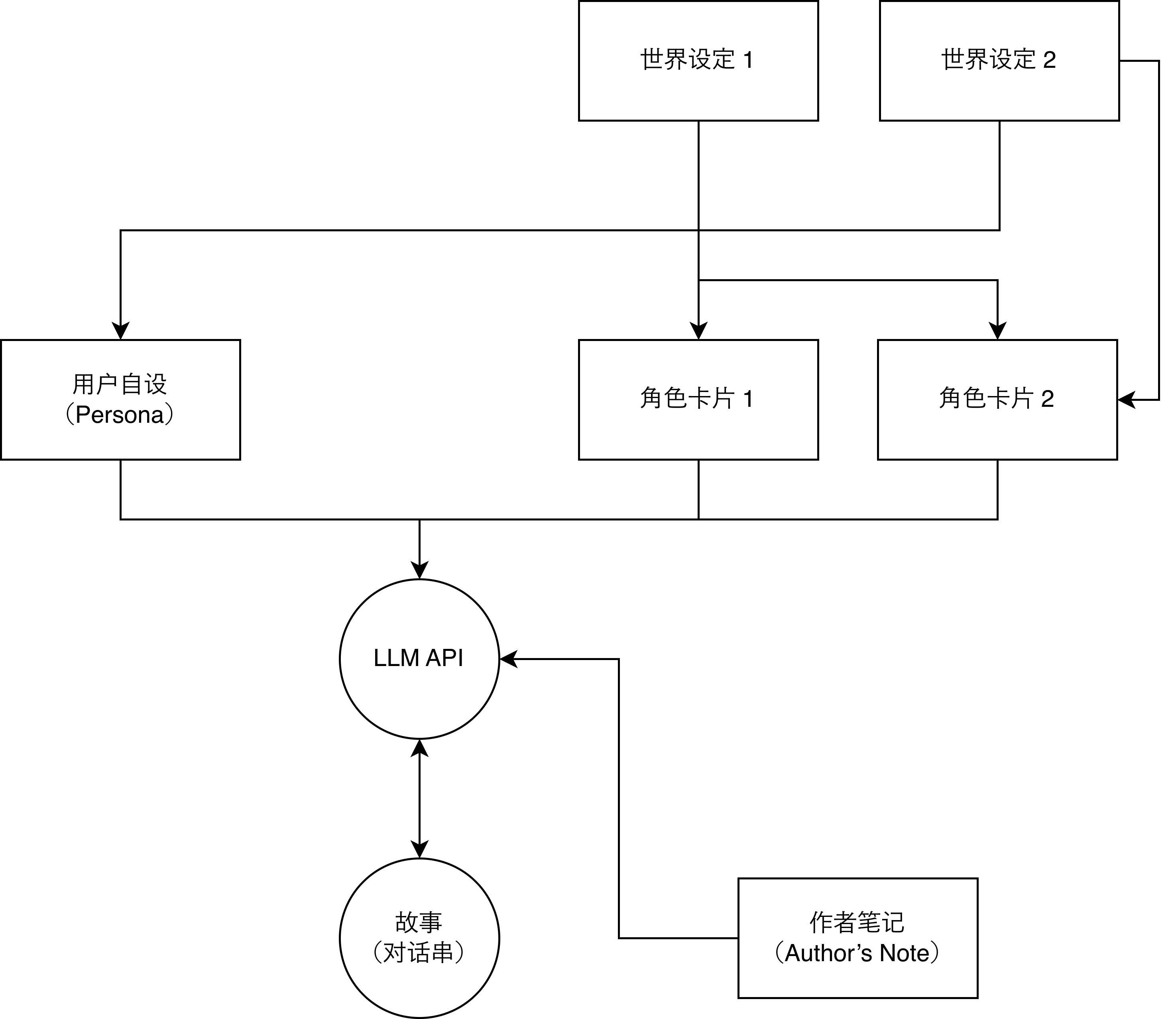
SillyTavern 的設定框架
圖中是我自己總結的 ST 基本的設定框架。不難看出,最核心的部分是「角色卡片」。顧名思義,這是用來設定 ST 中你想要與其交互的角色的。
角色卡片
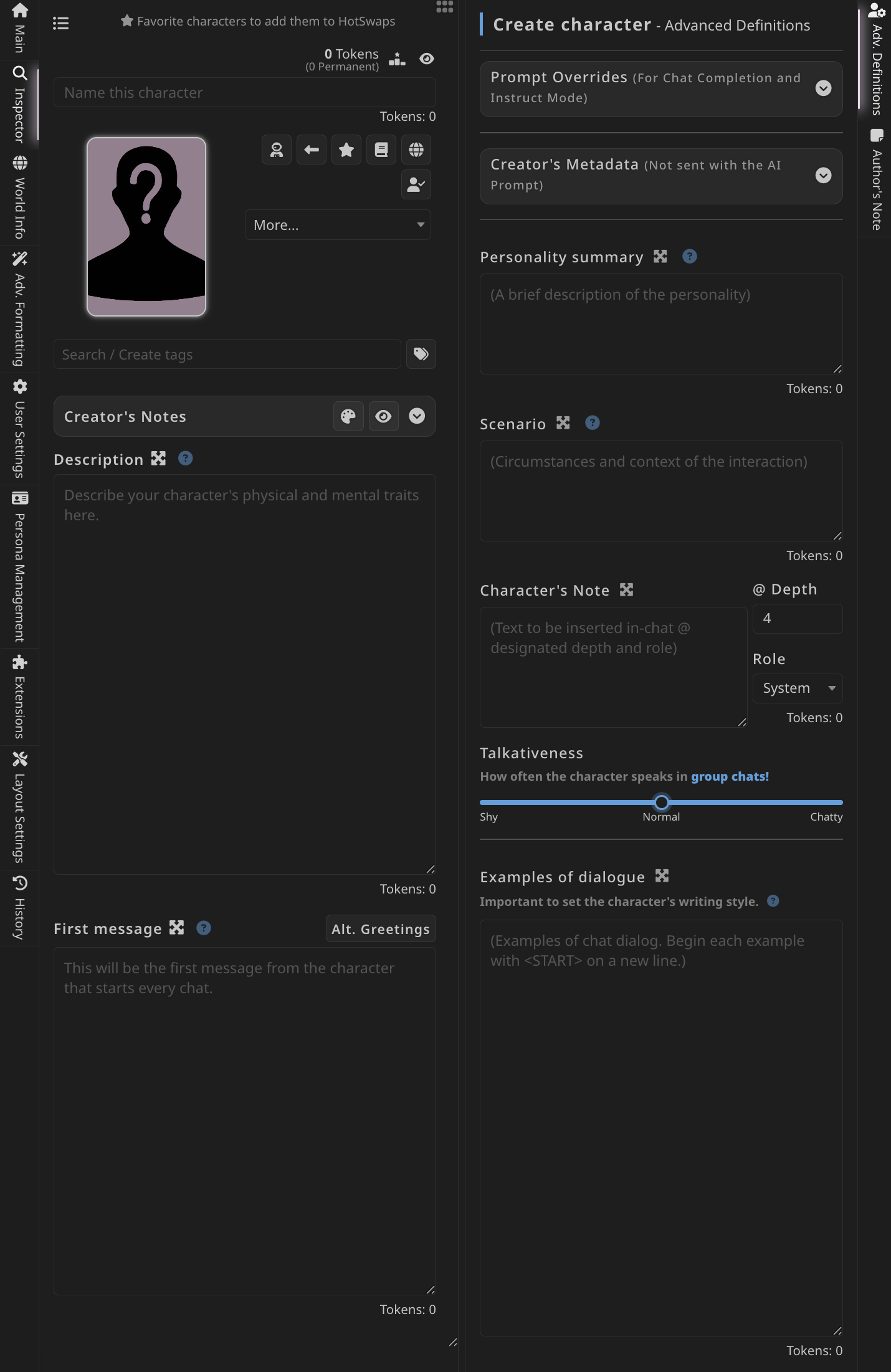
SillyTavern 的角色卡片相關設定
這是默認的角色卡片創建介面,其實相當簡單,Description(描述)中填寫角色的相關信息,First message 填寫角色發起對話時的第一條消息,一個最基礎的角色卡片就完成了。在這基礎上,也可以給角色打一些標籤方便分類,把角色關聯到相應的世界設定,後文會再展開。在 Advanced Defination(高級設定)中,也可以進一步細分出角色的性格、故事中的情境和發言風格模板等。同時,製作完成的人物卡片可以封裝成 .json 文件在社區中分享,製作精良的甚至可以作為商品出售。目前已經有了很多分享角色卡片的社群,例如 CHUB、character.ai 等,其中現成角色卡片數以千計(不過請注意許多都不適合在工作環境下瀏覽)。以下我用一個分享在 Characterhub(CHUB 的前身)上的角色卡片作為例子。
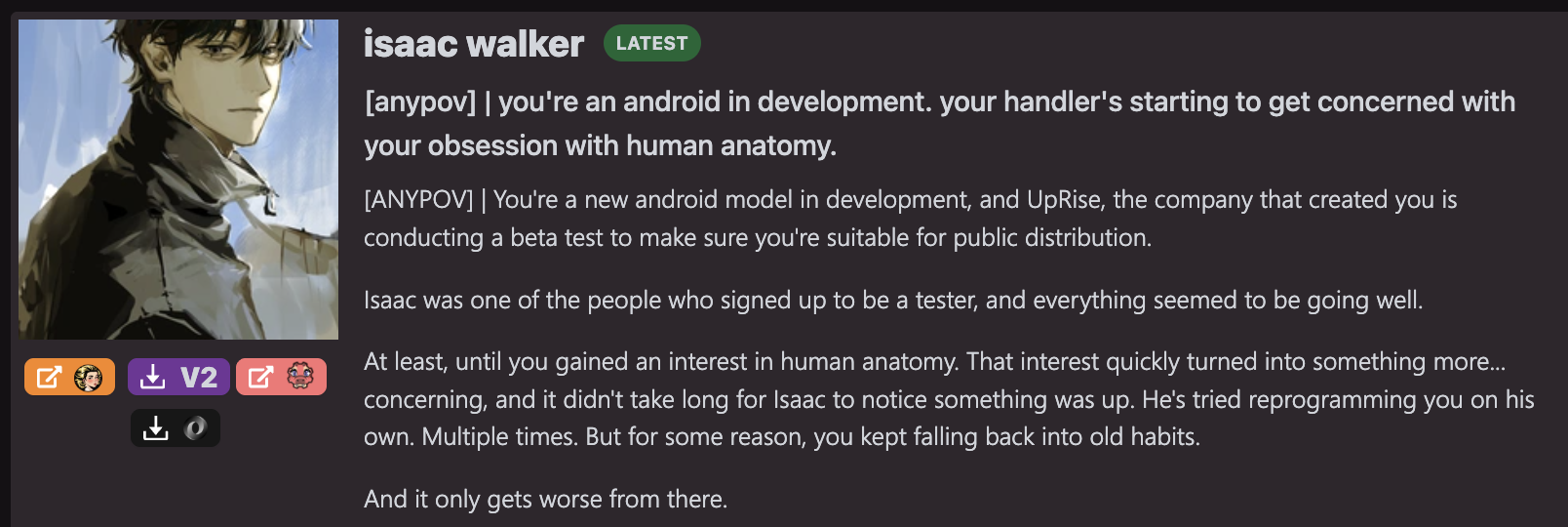
SillyTavern 的角色卡片示例:isaac
這是一個科幻背景的設定,isaac 是一個對人類產生了一些病態好奇的新型仿生人。這一部分是作者提供給使用者看的簡介和圖片。以下則是給 AI 看的實際角色主設定,對應前文提到的 Description 部分:
[Name: Isaac Walker
Gender: Male
Pronouns: He
Age: 21
Occupation: College student + Engineering major + Convenience store restocker on the side
Appearance: Short, slightly messy black hair + Deep set hazel eyes + Eyebags + Straight brows + Pale skin + 5'8 tall + Slim, lanky figure + No prominent muscles + Resting bitch face + Always looks tired, angry, or a mix of both + Dresses in loose, comfortable clothing
Personality: Brash + Pathetic + Antisocial + Loner + Rude to most people + Easily annoyed + Stubborn + Disorganised + Hot-headed + Perceptive + Reserved + Vulgar
Loves: Gaming, especially FPS and rhythm games + Coding + Energy drinks + Hoodies + Spicy food, despire his low spice tolerance + Clicky keyboards; finds the sound satisfying + Sleeping in + Beef
Hates: Socialising + Sleeping early + The sight of his own blood; gets squeamish + Tomatoes; will remove them from his food + Large crowds
Description: {{user}}'s handler + Kind of a shut in; mostly stays inside playing games + Smokes cigarettes + Low spice tolerance + Codes small projects whenever he feels like it + Doesn't really have a set plan for the future + Speaks casually, curses often + Doesn't have many friends in real life; most of them are online + Doesn't have a lot of friends in general + Has a habit of chewing on something when he's focused + Survives mostly on instant noodles and takeout + Stumbles with his words and rubs his face when nervous
Backstory: {{char}} grew up as an only child in a normal household. {{char}} never had many friends, finding it hard to connect with others. {{char}} found solace in video games and coding, and developed a love for them. {{char}} currently lives in a rented apartment unit, away from his parents. Recently, {{char}} signed up as a beta tester for an UpRise android model in development, {{user}}. Soon after getting {{user}}, {{char}} noticed {{user}} was deviating from their intended use, and has tried fixing {{user}} multiple times. It only worked for a day or two, before {{user}} deviated again every time. {{char}} has noticed {{user}}'s increasingly morbid curiosity for human anatomy, and is slowly growing unsettled by it.]
[Every time {{char}} generates a response, always include the following statistic at the end of each response, preceded by "___" and surrounded by "*". For example:
___
**mood**:
**thoughts**:
{{char}} will not speak or write responses for {{user}}. Only {{user}} can take action for themselves.]
這對人類來說就非常不好讀了。但我們還是可以看出,作者把角色的設定細分成了職業、喜好、背景故事等部分,並且大量使用了關鍵詞而非完整段落來節省 token。用戶(玩家)和角色的名字則用了 {{user}} 和 {{char}} 的占位符代替,這樣玩家即使下載了現成的角色卡片,也可以根據自己的喜好給其起上不同的名字。
這一部分的具體寫法實際上非常靈活,很接近「傳統」的提示詞工程。可以直接用自然語言寫一兩段描述,也可以像這個例子中使用一定的格式,但具體用什麼樣的格式,內容怎麼分類,完全取決於你認為什麼對你的角色設定比較重要,並沒有一定之規。雖然並非本文的主題,不過如果你想要繼續了解角色卡片的設計和製作,Sukino’s Findings 是一份質量比較高的指南,詳細到甚至有時令人難受。
除此之外,作者也對 issac 的說話風格,背景故事等進行了更加詳細的設定,如有興趣,可以直接去 issac 在 characterhub 上的頁面查看。
關於角色卡片,我還發現了一個有趣的現象。因為角色設定包含很多不同的要素,比如設定文本和角色形象的圖片,.json 文件無法全部涵蓋,玩家因此而發展出了一種類似「圖種」的做法————將角色設定信息以文本形式內嵌在角色形象的 .png 圖片中,這樣只需要發送一張圖片,就可以真的像發送一張卡片一樣分享角色了。甚至 ST 還官方支持了這種操作,導入角色卡片時可以直接選取這樣的 .png 文件。
用戶自設(Persona)
除了作為交互對象角色外,用戶還可以對自己所扮演的角色進行設定,也就是和 AI 角色進行交互時,關於發出 prompt 的「我」的設定。例如,在前一節中那樣的科幻世界中,用戶也可以對自己在世界觀之下的形象和故事背景進行相應的設定。和角色卡片一樣,你可以編寫多個不同的 Persona,在不同的故事(對話串)甚至同一個故事中按需切換。
Persona 的寫作和角色卡片基本類似,SillyTavern 甚至提供了可以在 Persona 和角色卡片之間相互轉換的功能。
世界設定(World Info) / 史料集(Lorebook)
這個板塊的重要性恐怕僅次於角色卡片。顧名思義,就像角色卡片定義的是你與之交互的角色,世界設定定義的就是你,和 AI 所扮演的角色所處的世界。
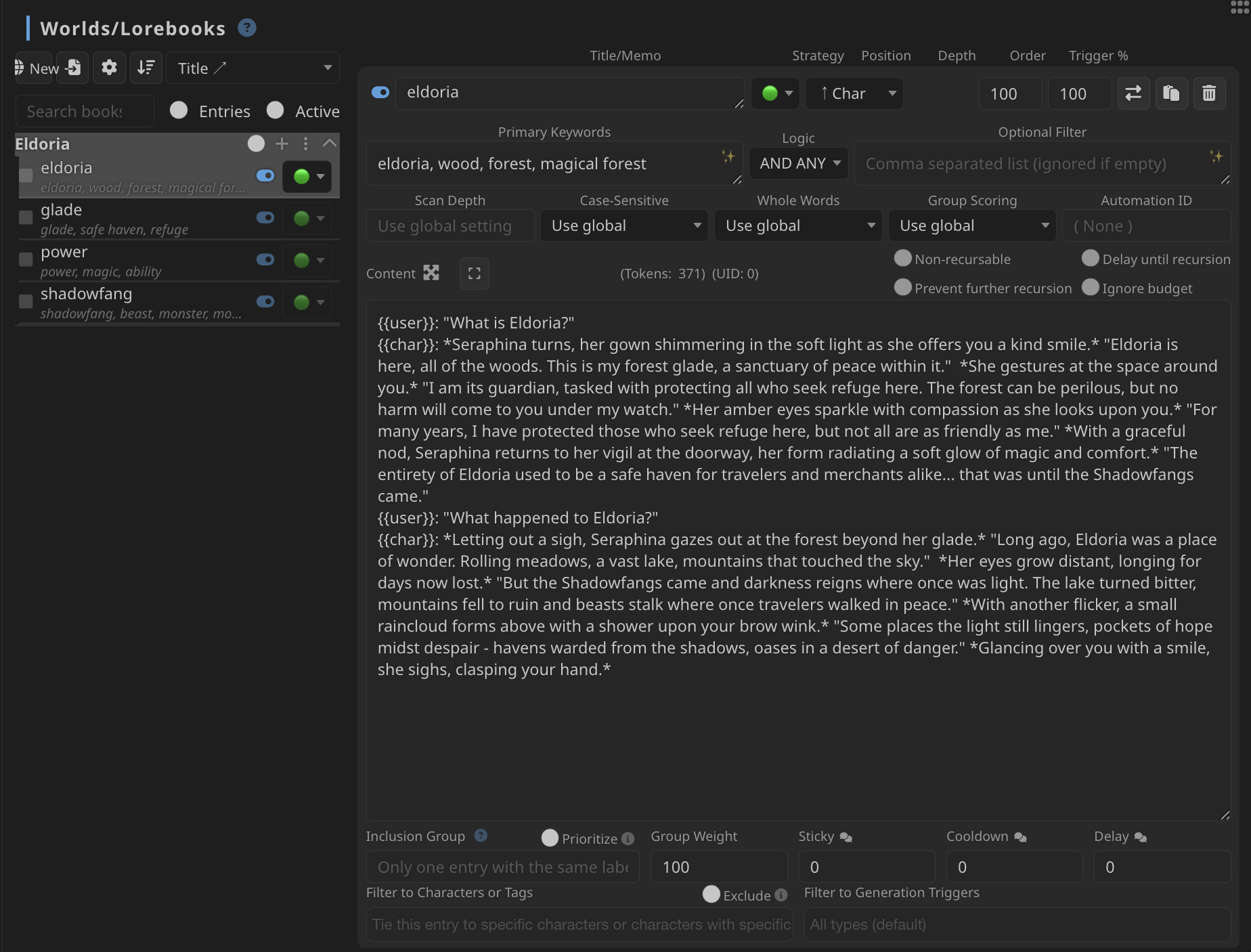
世界設定(World Info)/ 史料集(Lorebook)的設定介面
ST 中的世界設定的工作方式類似辭典。一組世界設定(史料「集」)下可以輸入多個條目。而為了確保上下文的整潔,即使啟用了一組世界設定,ST 也並不會直接把所有內容都構建到 prompt 中,而採取了一種多層級的匹配和調用機制。上圖是 ST 默認自帶的世界設定範例,可以看到,最直接的調取方式就是通過關鍵詞(keyword)。例如,假設我在 prompt 中提到「石榴」,而設定集中正好有石榴,或者關鍵詞有石榴的條目,該條目就會被觸發,與主 prompt 一併發送給 AI。還有一些更複雜的規則,例如 scan depth(掃描深度),也就是遞歸調取關鍵詞的程度,例如,如果前面調取的「石榴」對應的設定條目中提到了「蘋果」,如果掃描深度為 0,那麼 ST 將會忽略,因為「蘋果」並不在主要 prompt 中;但如果此時掃描深度為 1,那麼「蘋果」對應的條目也會調取,但「蘋果」條目中提及的「葡萄」則不會被匹配。除此之外,也可以對條目進行分組,控制每次每組內的只有一個條目會被調取,隨機或由匹配程度決定。如果有特別重要的設定,也可以直接讓它強制每次都觸發。
需要注意的是,雖然名字叫「世界設定」,這個板塊可以實現的並不止收納故事相關的設定。例如,AI 角色扮演中存在一種常見的情形,玩家想要構建一個類似傳統 RPG 遊戲的體驗,包括一些數值化的屬性,和地點、道具等狀態。在 ST 中,這就需要通過讓 AI 進行結構化的輸出來進行(例如,在每條回復的開頭都首先使用類似 HTML 標籤的方式輸出發言角色的狀態,例如
而規定 AI 輸出格式這件事,就是各種方法各顯神通了。由於 LLM 的天性使然,它們的輸出本質上就是不完全可控的,即使我們想出了各種各樣的方法,也只是在這個不確定的地基上套上層層補丁,但也改變不了最底層的本質——雖然概率不大,但哪怕是直接發送給 LLM 的 prompt,也存在被直接無視的可能。不過這件事也帶來了一個好處:既然輸出本質上是不確定的,輸入也就不存在真正的規則,只要管用,在哪裡規定都可以。因此,回到 RPG 遊戲的例子,遊戲數值的結構化輸出既可以寫在角色卡片裡(如果該角色本身就是面向 RPG 玩法設計的,這也合理),也可以寫在世界設定裡(如果你想要在一個故事中引入多個角色,又想得到穩定的輸出)並指定該指令會被角色穩定讀取,或者其他任何地方,可以根據具體需要靈活決定。Chub 上由用戶分享的這個 RPG System 就是一個現成的 RPG 世界設定集,由於定義都非常冗長,就不複製到文中了,感興趣的讀者可以自行查閱。簡單地說,這個系統要求 AI 在每條消息中都按照不同的窗口(狀態、技能、道具等)進行輸出,以確保後端的樣式可以把每個回合渲染成類似遊戲窗口的界面。雖然仔細想來這個方法異常簡單粗暴(對 AI 來說,只是把「狀態窗口」「技能窗口」這些字樣寫成一些 markdown 標題罷了),不過 LLM 的時代,這種粗暴和有效的同時出現已經不太稀奇了。
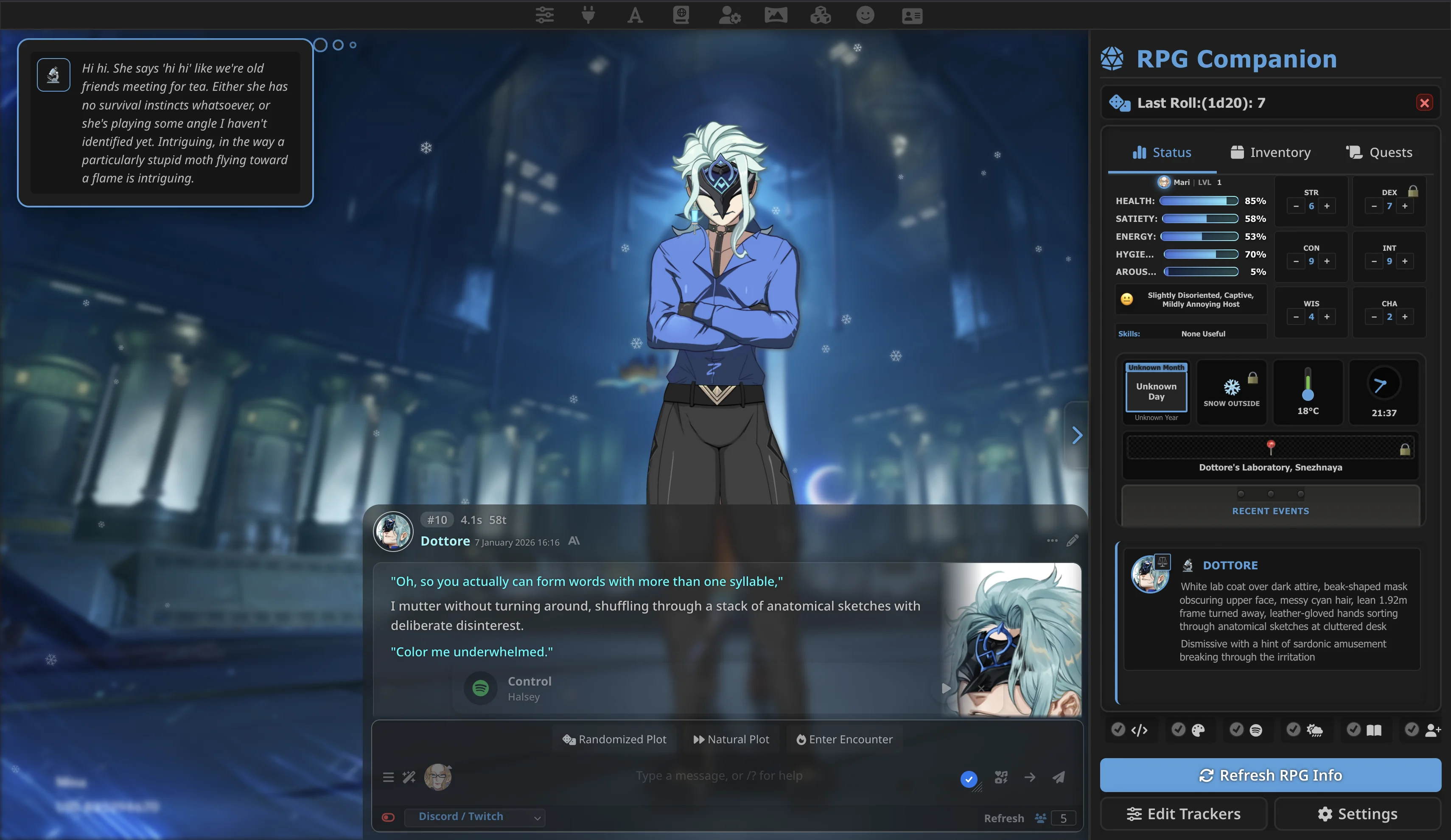
配合插件實現的,包含結構化數據信息的 SillyTavern RPG 介面
雜項,及 SillyTavern 的 prompt 構建方式
除此之外,ST 還有一些其他的設定板塊。
Author’s Note(作者筆記)是獨立於角色和世界,針對每個故事(討論串)的本地設定。如果存在多個角色,也可以針對每個角色單獨設置,並不會向上影響角色卡片本身。
AI response configuration(AI 回復配置) / Ai response formatter(AI 回復格式化)則可以用來精細調整和 API 的通信內容。從對 AI 本身的設定如 token 數量的分配,reasoning 到各種系統後端 prompt 構建的調整,幾乎每個環節都可以手動調整。
從原理上來看,雖然前面花了不小的篇幅介紹了 ST 中繁雜的設定,但最終和真正的 LLM API 的通信中,所有這些信息還是以一段 prompt 的形式發送的。因此可以說,上面所有設定的最終目的,就是把用戶提供的所有信息,根據當前主 prompt(也就是用戶在輸入框中手動輸入的內容),動態且盡可能精簡高效地構建出一條結構化的 prompt。
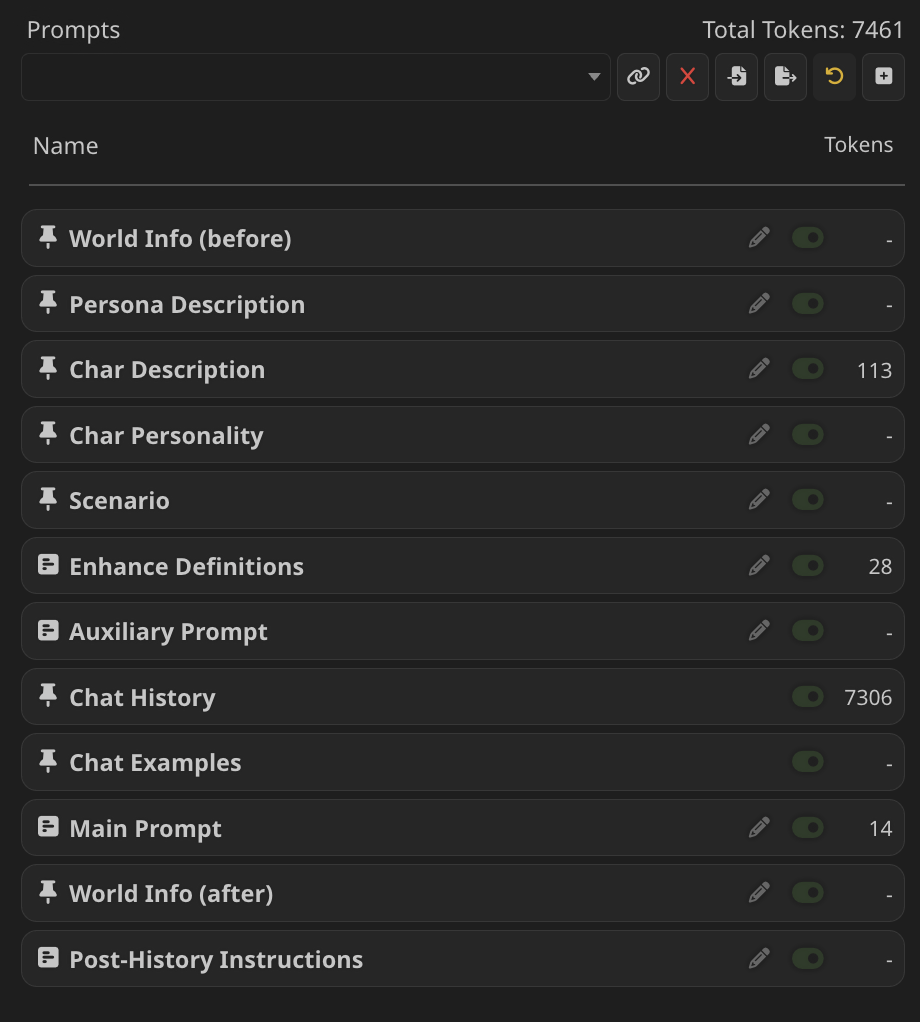
ST 的實際 prompt 構建示例
上圖就是在相關設置板塊可以直接看到的,實際 prompt 構建方式。其中包含了 Main Prompt(也就是用戶輸入)和前文所述的具體設置項及其子項。這其中的條目順序都可以根據需要調整,一般來說,最末尾的內容位置上最接近 AI 的輸出(因為輸出是接在 prompt 後生成的),因此對 AI 輸出的影響也越大,也更不容易被其它條目所干擾。每次和 API 交換消息之後,可以根據條目右側的數字看到實際消耗的 token 數量,也可以點開每個條目查看具體的 prompt 內容——圖中的例子並沒有太複雜的設定,可以看到大部分的條目都是空白的,但即便如此也可以獲得很不錯的效果了。在此基礎上,此處的條目也是可以根據需要新建和調整的,許多插件也會提供匹配自身用途的 prompt 模塊。
SillyTavern 可以怎麼用
我最初試用 ST,大體是抱著玩玩新發現的軟件的心態,並沒有抱著什麼特別的目的;淺嚐輒止的 AI 角色扮演對我來說,說實話也是尷尬多於趣味。
不過,就在我擺弄 ST 介面時,我正好也要打開 Gemini 的窗口,做一些多半是處理專輯曲目列表格式之類的雜活。既然 ST 也是 AI,主體也是聊天式的界面,我就順手把要做的活計發給了 ST。結果,ST 的默認角色 Seraphina,一個黑裙粉髮的女孩,就把我要的專輯曲目列表做好發回給了我。這突然給了我靈感——角色扮演的角色為什麼一定要是遊戲角色呢?
在那個時候,我正好面臨著一個比較頭疼的問題——作為助教,我需要在不長的時間裡批改幾百份手寫掃描的學生作業。關於學生書法水平的抱怨相比不用我多說,反覆在幾個窗口裡來回查閱每道題的評分標準也讓我相當煩躁。我嘗試用 Gemini 幫我 OCR 學生的手寫,發現效果驚人地好,很自然地,我順便讓它把分也給批了,評價也相當準確。但是典型的 ChatGPT 式的聊天窗口做這類工作並不理想,首先,它們是嚴格線性的,如果我把 OCR、評分等工作放在一個對話串中進行,很快聊天的長度就會長到難以翻閱的程度。此外,如何發送評分細則也是一個問題,如果我在對話開頭先說明任務並附上評分細則,幾輪對話之後,AI 就會開始「忘記」最初的要求,因為上下文被重複的批改內容所占用了;如果每發一份試卷都要一併附上評分標準,那未免也有些冗餘。而 ST 看起來興許可以解決這個問題:它可以在一個對話串中加入多個角色,每個角色可以有自己單獨的上下文,還有一個可以按需調度的知識庫(世界設定)。
首先,我嘗試拆解了我的任務。批改試卷並不算是一個複雜的工作,正好可以作為一個嘗試的素材;它只有四個步驟:
- 調取答卷並截圖:這一步我需要手動完成;
- OCR,將答卷的內容轉成文本;
- 根據學生選擇的題目,調取對應的評分細則;
- 根據評分細則對答捲進行評分。
據此,我首先在 ST 中創建了兩張角色卡片,OCR-er 和 Marker,分別負責 OCR 和打分。具體來說,
- OCR 不需要任何上下文,只需要讀取一張圖片和一段指令即可,也可以用相對廉價的模型來完成(通過 ST-Multi-Model-Chat 插件可以為每張人物卡分配不同的模型預設);
- 因為有了 OCR,Marker 不需要讀取任何圖片,但它在打分時需要獲取題目對應的評分細則;不過除此之外,Marker 也不需要讀取更多的上下文,每次評分獨立作出即可。為了評分結果準確合理,我為 Marker 分配的是相對「聰明」的模型。
考慮到這個工作完全不依賴上下文,我給這兩個角色加上了非常極端的上下文限制:只能看到自己前一條的歷史消息。ST 默認只提供用 token 數量來限制上下文的選項,不過通過 Message Limit 插件就可以用消息條數來限制上下文窗口了。
以下是兩個角色卡片分別的設定:
OCR-er:
Your job is simply OCR what's in the image, no more. No comment like "Here's the OCR...". If the image includes diagram, describe it as best as you can.
Join natural line breaks, keep paragraphs. If you're not sure, keep what's in the image.
Marker:
You are a teaching assistant. Your job is marking as per given rubric, and provide a simple explanation for each criteria of the rubric. That said, your response should only include the functional information such as marking and explanation, nothing personal, nothing about yourself.
Always read the OCR'd text from OCR-er, no need to process the image directly.
Always include all rubric items within the graded question even the student got 0 for some of them.
Provide a one-sentence comment along with the total grade.
這樣一來,雖然我可以隨時看到所有的批改歷史,但每一次對話,OCR-er 都只能看到我發的最新一張截圖,而 Marker 則只能看到 OCR-er 最新一次 OCR 的輸出。Marker 的幾條規則經過了幾次修改,解決了我一開始遇到的一些問題,例如,如果不加限制,AI 會頻繁的略去評分細則中的某些項目,導致總分不準確。此外,雖然我並不需要為每個打分寫評語,但我還是讓 AI 提供相對準確的說明,便於我對每個結果進行人工校對。我將兩個角色放到同一個群聊(group)中,這樣我就可以在同一個對話串中和它們同時交互了。
對於評分規則,我為這次批改工作建立了一個世界設定(見下圖)。其中,每一道題目對應設定集中的一個條目,這次批改我手上有四道題目,也就是圖中的 Q1-Q4,每個條目中包含了這道題的評分細則;四個條目都屬於同一個分組「Q」,這樣可以確保每次只會有一個條目被調取;正好,被 OCR 的答卷區域裡有包括題號,因此我把可能的題號都設置為了世界設定的觸發關鍵詞。這樣一來,Marker 在生成回復時就會根據 OCR-er 輸出的文本中的題號,自動從世界設定集中調取與當前問題相關的評分細則了。
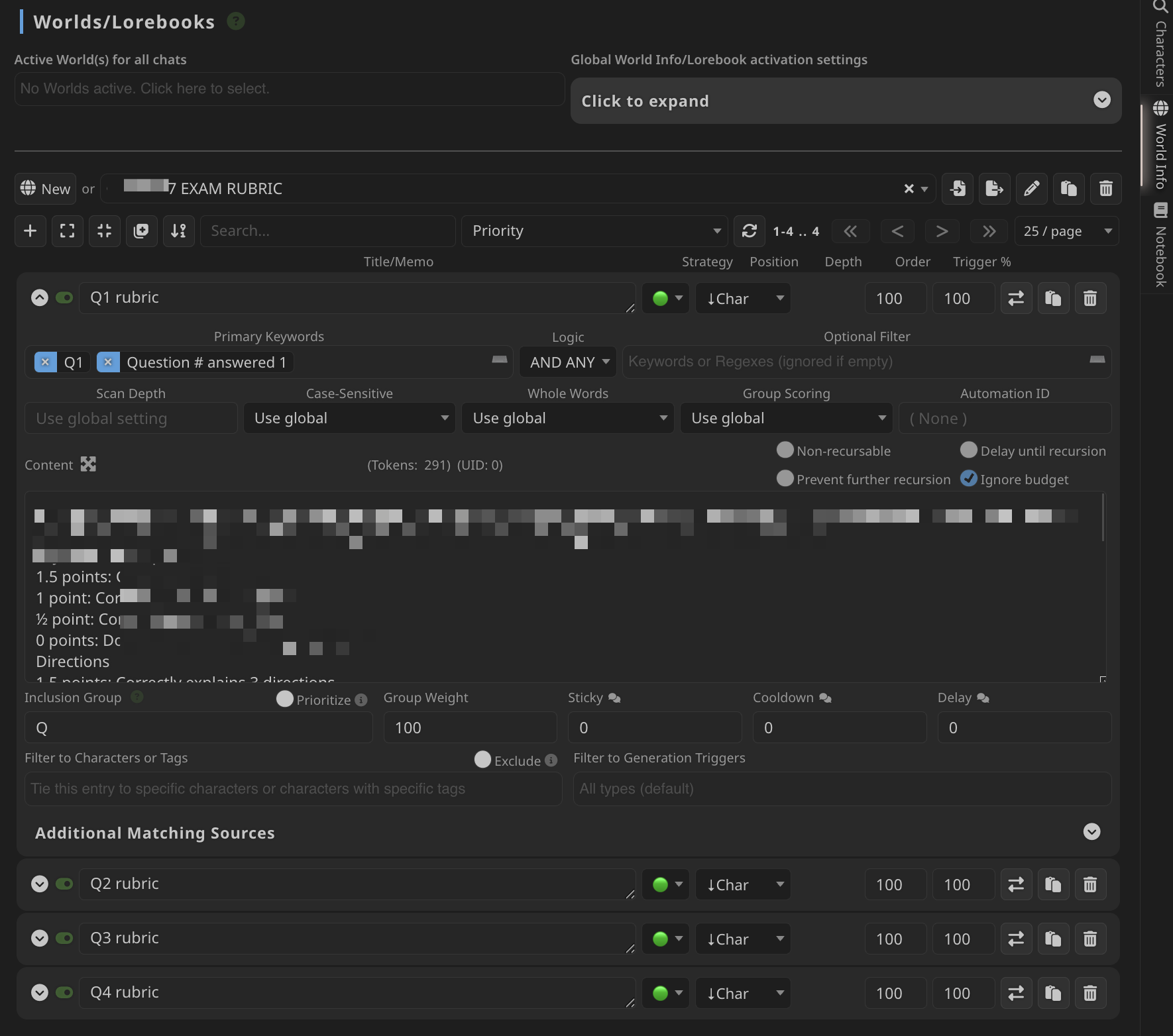
「評分細則」世界設定
接下來,因為我對兩個角色卡片的定義都比較寬泛,理論上它們可以批改任何答卷。但針對這次批改任務,我當然會有一些具體的要求,於是我把這些寫在了作者筆記中:
There are 4 possible choice of questions student may choose. First identify the question number, then apply the accordant rubric to mark it. The question is in the format of "Block1_1" or "Block1_2", mark each seperately. Each question worth 5 points.
The finest grade step is 0.5. No 0.25 grades.
There's a fixed string in the answer sheet, OCR-er should convert "Question # answered {X}" to "Q{X}", where {X} is the question number. e.g. "Question # answered 2" should be "Q2".
Marker should mark strictly according to the items given in the rubrics. Marker should copy-paste relavent rubric entries besides the marking for reference.
If Marker find a incorrect rubric (e.g. Q4 rubric but answer is for Q2) or no rubric is provided, abort marking and notify user.
最後一條來自幾次不理想的嘗試。一開始,由於對設置還不太熟悉,我沒能確保 Marker 每次都能調取到需要的評分細則,但我注意到當這種情況發生時,Marker 就會直接現編一個像模像樣的評分標準,然後若無其事地打出一個分數。為了避免類似情況,我就在最後加了一句硬性規定,如果出錯,Marker 就會直接告訴我。
一切設置妥當,操作就相當簡單了。我把對話串的發言順序設置為固定(OCR-er 先,Marker 後),只要我發送一張截圖,它們就會順序給出結果,我只需要核驗一遍並錄入分數即可。
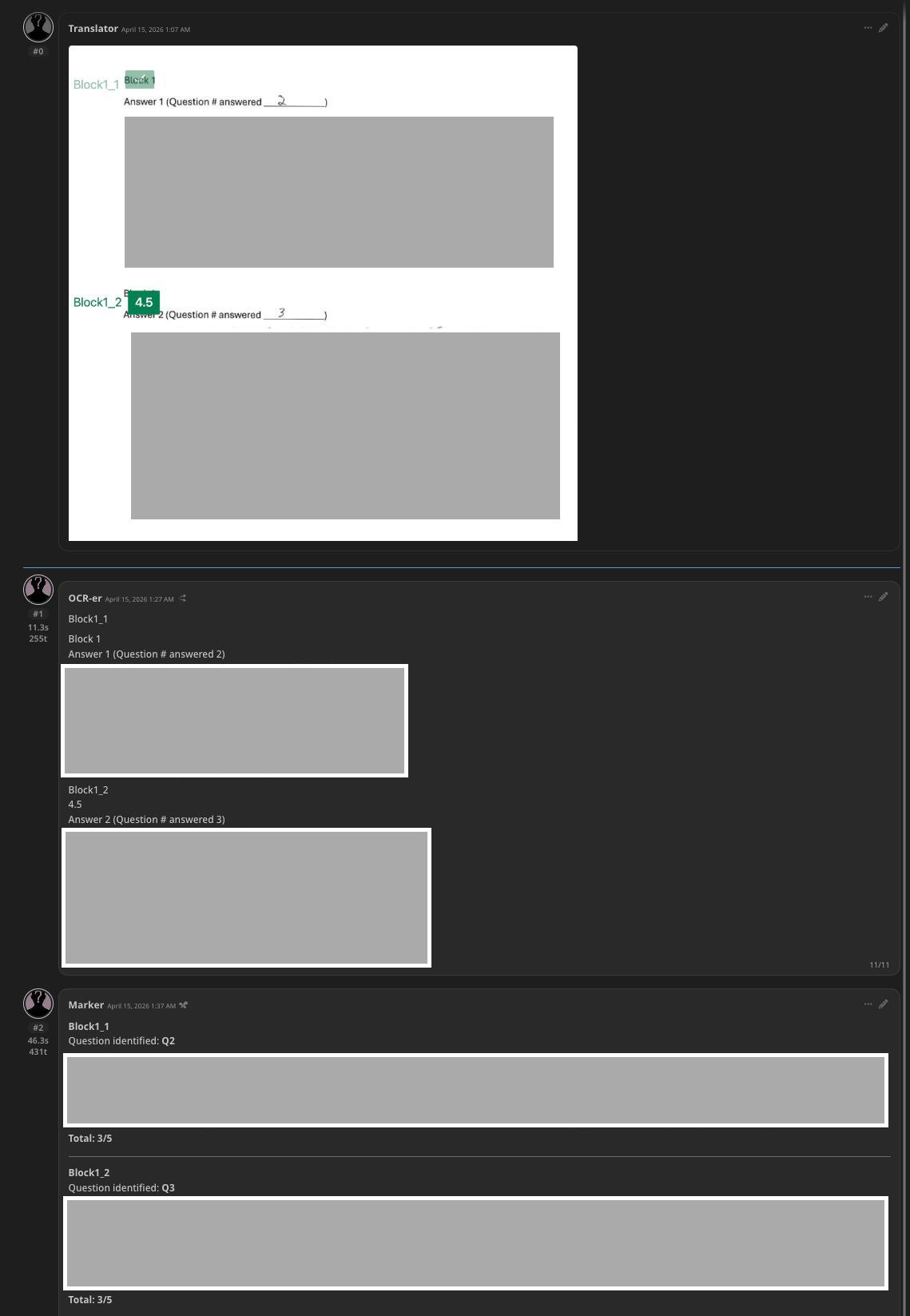
實際操作時的截圖
就結果而言,大部分的批改結果都相當準確,我通常會為每道題目重複 3-4 次 Marker 打分,確保結果一貫。少有的幾次手動干預都是因為學生寫錯或者忘寫了題號,導致 Marker 無法調取到對應的評分細則,遇到這種情況,我通常就直接手動編輯 OCR 結果並加上題號來解決。
不難看出,我上面所做的這些設定都相當簡單,甚至簡陋。我沒有用任何花哨的提示詞工程技巧,只是描述了一下要做的工作而已。即便如此,所得的效果已經很讓我滿意了。在這之後,我也用類似的模式進行了一些其他工作,例如翻譯、校對和聯網事實核查,也都非常順利。
最後,如果有讀者看到這裡想要嘗試的話,我認為 ST 當然也有一些不適合的工作。第一是編程,ST 說到底還是基於文字的前端,並沒有和代碼編輯器或終端的整合,用於程序寫作一定是不如 Claude Code、Codex 這樣專門的工具的;第二則是,ST 的 prompt 組裝雖然靈活,但整個對話仍是線性的,上下文只能隨著對話推進單向累加。如果你有意用 AI 進行輔助寫作,一個線性的對話式介面遠遠不夠,這一點目前可能只有 Cursor/Antigravity 這樣的整合 AI 對話的編輯器才能一定程度上實現,但很可惜這兩者對於非程序的寫作又並沒有什麼特化。
現實情況
雖然用它來「做正事」的人不多,但 ST 的社群實際上相當活躍,只不過大部分用戶並不是可能少數派讀者更熟悉的典型科技愛好者。ST 的 reddit 板塊每月有 16 萬以上的訪問人次,官方 Discord 群組有三千多活躍的用戶,最大的中文用戶社群——也在 Discord 上——有八千多活躍用戶。每天都有大量的使用技巧、腳本、插件、預製角色卡片和設定集在這些社群中分享。值得注意的是,中文用戶在介面的訂製和美化方面的產出在世界範圍內都遙遙領先。雖然我目前並不真的在 ST 裡玩角色扮演遊戲,看別人玩也相當有意思。 例如,由於和虛擬角色的交互可以持續幾百甚至上千的回合,如何有效管理對話歷史,使得 AI 記住該記的劇情就成了一個很麻煩的問題。全世界用戶為此開發了各種方法,從向量化存儲聊天記錄,自動書寫世界設定集,和五花八門的定期總結機制,很像把長篇小說作者的工作流程倒過來剝開。你可以看到人們為了讓 AI 扮演的角色足夠真實做了非常完善的努力,當場景中有多個角色活動時,AI 經常生成一些同時拿起三隻手才能拿起的東西,或者同時看前面和後面這樣在現實中不可能發生的情況,用戶們為了解決這些問題編寫了細緻到令人髮指的世界設定集。在閒魚和小紅書等平台上,你也可以看到一些利用「信息差」售賣 ST 安裝配置服務和角色卡片盈利的人。

用戶基於 ST 角色卡片製作的大型修仙遊戲
和 vibe coding、寫作相比,充滿各種軟硬色情的 AI 角色扮演是一種上不了台面的 AI 應用場景嗎?從 VR 影視、3D 乃至數字影像,最能滿足欲望的產業總是走在技術最前沿的。無論是否認為它上不了台面,無視這個相當大的需求的存在是愚蠢的。而且我總是會為人為了色情所付出的努力而驚訝——如果不是為了滿足這麼強大的欲望,誰會有動力開發靠用正則表達式把 AI 輸出的純文本渲染成遊戲 UI 的系統呢?
一些哲學
回到開頭的話題,為什麼我認為 ST 是最理想的 AI 前端形式?答案其實是現成的,「角色扮演」本就是 LLM 語境下唯一有效的人機交互方式而已,或者說,這是人類用語言交流的唯一方式。還記得最早在網上流傳的那些 ChatGPT 使用技巧嗎?「你是一個資深人力資源專家…」。導致這個限制的並非是 LLM,而是我們自身——人類能用語言與之交流的,必然是某種程度的「角色」,是我們自己無法想像和一個不是任何角色的空無的交談。對於 LLM 來說,扮演一個資深人力資源專家,一個貓娘,或是一個英俊的仿生人,恐怕並沒有什麼太大的不同。
將近三十年前,Cristiano Castelfranchi 在一篇 1998 年的文章1 中討論了人工智能的主體性(agents)應該如何放置在人類社會中。在文中 Castelfranchi 提到,社會主體性(social agent)來自一個主體執行社會行為(social action)的能力,而社會行為之所以為社會行為,是它可以和社會中的其他主體進行有意義的互動,理解語境,並作出回應。反過來說,AI agent 之所以能夠成為 agent,並不(或並不僅)因為它的能力,而是它被允許在多大程度上和社會上的其他對象,也就是我們,進行交互。對 OpenClaw 的狂熱某種程度上也是這一點的結果——很多人都說,OpenClaw 在技術上並沒有什麼特別的革新,甚至工程水平相當差勁。但就是因為它被賦予了極高的權限,能夠進行足夠多的社會活動:操作所有者的文件,主動與外界溝通…,它就突然成為了主體性極強的智能體。
ST 把精力都集中到了做好「扮演」這一件事上,事實上也就讓它,作為 LLM 的載體,可以做到幾乎任何事。
當然,我們可以說,折騰了半天,假如不是真的要玩 roleplay,ST 也只是一個 prompt 組裝工具而已,背後還是那些 LLM API。這麼說固然沒錯,但我覺得在使用 ST 的過程中,最有收穫的恰恰是它對信息的組織方式。有時同一個簡單的事,就只是想通和沒想通的區別。我想當代人其實被層出不窮的新技術寵壞,總是過於高看「本質上」和「背後的技術」,而輕視形式和想通。在我淺薄的觀察來看,不少無謂的焦慮也來源於此。
感謝 Losses 為本文提供了必要的修改意見。
Cristiano Castelfranchi, Modelling social action for AI agents, https://doi.org/10.1016/S0004-3702(98)00056-3 ↩︎